
We, at Zartis have recently launched a new service for the employees community, focusing on delivering live presentations and producing high-quality video content on various technical topics. To that end, we wanted to identify the team members who are active cotributors of our community and activate them as content creators. In this article, our team member and Senior Software Engineer, Augustyn Binkowski, explains how he developed a .NET console app to anonymize and aggregate Slack data for analysis with ChatGPT-4o, how we ensured privacy, how we went about data verification and refinement, among other things.
We hope our experience and insights help you in navigating through similar challenges!
The Problem
To ensure the success of this service, it is crucial for us, as service administrators, to understand the interests of the Zartis members and identify the most active users who can be invited as contributors.
Our internal Zartis Slack channel, #tech_community, is the perfect source for this information, as it has been a hub for sharing interesting topics and tech articles for a long time. However, the sheer volume of data in this channel presents a significant challenge. Manually sifting through countless messages to extract valuable insights is not feasible. Therefore, we need an efficient method to analyze this data and extract essential information, such as trending topics and key contributors, to make informed decisions about our service offerings.
Recognizing the importance of this task, I volunteered to take on the challenge of solving this problem and delivering the valuable insights we need. My goal is to efficiently analyze the data and provide actionable information that will help shape our new service.
Potential Solutions
To challenge the data analysis problem from the #tech_community Slack channel, I decided to leverage the easy access Slack provides for exporting data in JSON file format. By requesting these backup files from our administrators, I gained a semi-structured dataset ideal for my analysis. You may ask yourself why do I refer to the data as semi-structured? After all, it’s a JSON file. Despite the structured nature of JSON, Slack threads are represented as nodes with a good amount of metadata, and values as long strings of text that require thorough analysis.
The ideal solution for my analysis should strike a balance between the time and effort invested and the accuracy of the results. In this initial phase, I considered four potential solutions:
-
- Manually reviewing Slack
- Using available AI tools for Slack data analysis
- Implementing full enterprise text data analysis with token extraction
- Conducting data analysis using ChatGPT
Manually reviewing Slack is too laborious and impractical, especially if repeated analysis is needed in the future. Using available AI tools for Slack data analysis could be effective, but these tools are often paid services, raising concerns about data privacy due to the sensitive nature of the data. We are talking about my colleagues’ full names and their interests. Implementing full enterprise text data analysis with token extraction is as we say it in the Polish language “shooting a sparrow with a cannon,” involving an excessive amount of work for relatively simple JSON file analysis. Conducting data analysis using ChatGPT provides a hands-on approach to leverage AI for parsing and analyzing the data.
After careful consideration, I immediately discarded option 1 due to its impracticality and option 3 because it involves an unnecessary level of complexity for my needs. This left me with options 2 and 4. However, due to cost and potential data privacy issues with market AI tools, I opted for solution 4, utilizing ChatGPT for data analysis while keeping data privacy considerations in mind. More about this approach and how I addressed the privacy concerns will be discussed in the next chapter.
Zartis AI Culture and ChatGPT Challenges
Zartis AI Usage Policy
At Zartis, we have an AI usage policy that governs how we use AI tools while ensuring the confidentiality and security of both our data and that of our clients. According to our policy, employees can only use approved AI tools within specified use cases. It is imperative not to upload or share any confidential, proprietary, or regulated data, such as documents, code, tests, and meeting minutes, to any AI tools.
When using AI tools, we are also required to turn off chat history and prevent the tools from using our data to train their models. As a precaution, we should always ask ourselves if we would upload the data to social media or a public GitHub repository. If the answer is no, then we should not provide the data to the AI service.
In the context of using ChatGPT for data analysis, as long as the data is anonymized, it aligns with our AI usage policy. Anonymized data mitigates the risk of exposing personal and sensitive information, making it acceptable to use ChatGPT under the guidelines provided.
The Anonymization Challenge
The primary challenge in using ChatGPT for analyzing Slack data is ensuring proper anonymization. The Slack data, provided in JSON file format, consists of daily files named according to the format YYYY-MM-DD. Each JSON file contains an array of nodes representing Slack threads. These threads include various properties such as ID, user ID, text value, user profile, replies, reactions, and more.
To anonymize a Slack thread node effectively, I need to traverse all its properties and identify those that contain sensitive data. This involves not only the obvious fields like user IDs and user profiles but also examining the text values for any personally identifiable information. Once identified, these data points need to be anonymized to comply with our data privacy standards. This process ensures that while the data retains its utility for analysis, it does not compromise the privacy of our colleagues or the integrity of our compliance with data protection regulations.
The Aggregation Challenge
To extract valuable data like the top 10 most popular tech topics in 2023 or the top 10 most active users, I need to address an additional problem: each day is packed in its own JSON file. This means uploading 365 files to perform data analysis with ChatGPT is not feasible. To overcome this issue, I need an aggregation solution in addition to anonymization.
Example Slack Thread Node
The following example illustrates a redacted Slack thread node from the Zartis data set. This JSON snippet demonstrates the structure of a typical Slack message, which includes user information, message content, and various metadata.
| { “user”: “–REDACTED_USR_ID–“, “type”: “message”, “ts”: “1714983143.406889”, “client_msg_id”: “–REDACTED_MSG_ID–“, “text”: “Hey guys.\n\nIn the project I work we need to generate PDF documents in .NET on the backend. I’m looking for a tool to generate those documents.\n\nIn the past I was using ActiveReports and then WkHtmlToPdf. Currently, we investigated Syncfusion (does not allow backend-only rendering) and IronPdf (costly).\n\nDo you know any other solutions?\n\nRequirements:\n• Easy to learn and implement (time is critical)\n• Footers\/Headers support\n• Page numbering\n• Generating charts\n• Nice to have: Document digital signature\n• Nice to have: Renderer hosted outside of main app (for scaling)\n Best,\n @<–REDACTED_USR_ID–>”, “team”: “–REDACTED_TEAM–“, “user_team”: “–REDACTED_TEAM–“, “source_team”: “–REDACTED_TEAM–“, “user_profile”: { “avatar_hash”: “–REDACTED–“, “image_72”: “–REDACTED–“, “first_name”: “John”, “real_name”: “John Doe”, “display_name”: “John Doe”, “team”: “–REDACTED_TEAM–“, “name”: “john.doe”, “is_restricted”: false, “is_ultra_restricted”: false }, “thread_ts”: “1714983143.406889”, “reply_count”: 9, “reply_users_count”: 6, “latest_reply”: “1715003549.108589”, “reply_users”: [ “–REDACTED_USR_ID_1–“, … ], “replies”: [ { “user”: “–REDACTED_USR_ID_1–“, “ts”: “1714983346.709959” }, … ], “is_locked”: false, “subscribed”: false, “blocks”: [ { “type”: “rich_text”, “block_id”: “g0KvG”, “elements”: [ { “type”: “rich_text_section”, “elements”: [ { “type”: “text”, “text”: “Hey guys.\n\nIn the project I work we need to generate PDF documents in .NET on the backend. I’m looking for a tool to generate those documents.\n\nIn the past I was using ActiveReports and then WkHtmlToPdf. Currently, we investigated Syncfusion (does not allow backend-only rendering) and IronPdf (costly).\n\nDo you know any other solutions?\n\nRequirements:\n“ } ] }, { “type”: “rich_text_list”, “elements”: [ { “type”: “rich_text_section”, “elements”: [ { “type”: “text”, “text”: “Easy to learn and implement (time is critical)” } ] }, … ], “style”: “bullet”, “indent”: 0, “border”: 0 } ] } ], “reactions”: [ { “name”: “pray”, “users”: [ “–REDACTED_USR_ID_6–“ ], “count”: 1 } ] } |
This example contains various properties that need to be redacted or altered to ensure privacy:
- user
- user_profile (all fields within this object)
- team
- reply_users (all values in the array)
- replies (all user values within each object in the array)
- Any personal names or identifying information within the text field
By ensuring these fields are anonymized, the data retains its utility for analysis while protecting the privacy of individuals.
The Solution
Step-by-step Plan
To be able to repeat the data analysis in the future I came up with a step-by-step plan:
- Get the Slack backup data from administrators – request the backup files for the desired period, ensuring access to all daily JSON files.
- Run the data through the anonymization tool – an anonymization tool will traverse each JSON file and redact sensitive information. This process will produce two files. The anonymized data files containing the Slack data are suitable for analysis. The sensitive data file that holds the original sensitive data, allows me to map anonymized user IDs back to their original values if needed.
- Aggregate the data – combine the daily JSON files into aggregated formats such as yearly, semesterly, quarterly, or monthly, depending on the range of dates I want to analyze. This step ensures that I have a manageable file size for uploading and analyzing.
- Upload the anonymized file to ChatGPT for data analysis – upload the aggregated anonymized file (e.g., for the year 2023) to ChatGPT and formulate queries to extract insights. For example, I might ask, “What are the top 10 most active users in 2023?”
- Review the chat’s response and tweak the query if needed – analyze the responses from ChatGPT and adjust the queries to refine the results. This iterative process helps ensure that the data insights are accurate and meaningful.
- Map the results back to the original data – once the results are satisfactory, use the Sensitive Data File to map the anonymized user IDs and other redacted information back to their original values. This step allows me to present the findings in a comprehensible and actionable manner while maintaining data privacy throughout the analysis process.
By following this plan, I can efficiently analyze the Slack data, extract valuable insights, and ensure data privacy and security. After all, I do not want any big tech CEO’s prying nose getting insights into my colleagues’ interests.
The Slack Data Anonymizer Tool
The Slack data anonymizer is a .NET console application designed to handle both data anonymization and aggregation. You can find the source code on GitHub. I developed this tool myself without AI assistance, as I enjoy coding these types of solutions.
The application provides two key features:
- Data Anonymization: It processes Slack JSON files to redact sensitive information, producing an anonymized dataset. Additionally, it creates a sensitive-data.json file to map anonymized IDs back to the original data if needed.
- Data Aggregation: It aggregates daily JSON files into larger timeframes, such as yearly (YYYY.json), monthly (YYYY-MM.json), or quarterly (YYYY-Q1.json), depending on the selected mode.
In developing this solution, I utilized techniques from a previous tech blog on asynchronous data streaming with HTTP and JSON in .NET and JavaScript. I treated individual JSON files as asynchronous streams of objects, processing them one by one and then merging these streams into a final result stream saved to the anonymized output files. This approach enabled efficient handling of large datasets while maintaining data privacy.
How it works

The provided architecture diagram illustrates how the tool works:
- The tool reads individual JSON files (e.g., 2019-04-01.json) through ReadRepositories.
- These streams are passed to MessagesService, which utilizes various anonymizers (e.g., MessageAnonymizerService, TextAnonymizerService, RepliesAnonymizerService).
- The anonymized data is then written to MessagesWriteRepository, producing aggregated files (e.g., 2019.json, 2020.json).
- Sensitive data is separately written to SensitiveDataWriteRepository.
The streams of Slack threads are simply concatenated without any complex logic like zipping. The main challenge was to write these streams into specific files, which was addressed by using the .NET built-in channel structure.
ChatGPT Queries and Results
It was time to put ChatGPT’s data analysis to the test. I uploaded the anonymized and aggregated JSON file for 2024 and began with the query,
“What are the top 10 most interesting topics in 2024 in this file?”
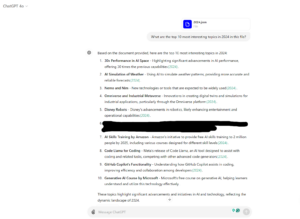
Within seconds, ChatGPT provided a list of potential topics I could use. Although I had to remove some outliers, like issues with internal tools, most results were accurate. ChatGPT effectively categorized topics, grouped them, and tallied the number of replies and reactions to determine the top discussions.
Next, I asked,
“What are the top 10 most active users in 2024 in this file?”
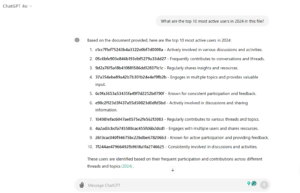
The response included valid results but also listed Slack bots. To refine the data, I adjusted the query to exclude specific IDs:
“What are the top 10 most active users in 2024 in this file, excluding:
* 1cc7f1ef75243b4a3322e0bf7d0008a
* 05c6bfe903e846b193dbf5279a33dd27?”
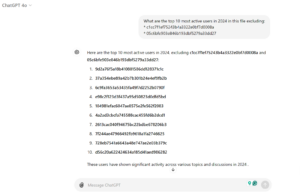
This adjustment yielded accurate user data after mapping anonymized IDs to real users using the sensitive data file.
I then tried to cross-reference users with their interests, asking,
“Cross-reference these users with the topics they were interested in?”

The results were somewhat disappointing, as they included trivial topics like the party parrot emoji among the most important.
Finally, I queried specific user interests:
“Can you give me the topics that this 9d2a76f5a18b410881586dd128371c1c user is interested in? Please explain the results.”
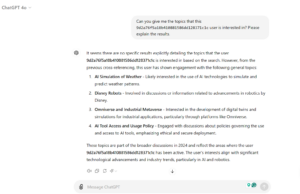
The request for an explanation was particularly useful, as it provided context that confirmed the accuracy of the results. In this case, ChatGPT’s analysis was spot-on, accurately reflecting the user’s interests.
Conclusions
This project demonstrated the importance of programming skills, as they enabled me to address two key challenges: anonymizing and aggregating data before using ChatGPT for data analysis.
Despite assurances from our ChatGPT license that Zartis workspace chats are not used for model training, it is prudent to remain cautious, especially in light of frequent data leaks. Each interaction with ChatGPT should be handled carefully, given the sensitivity of the data involved.
ChatGPT, while powerful, is still just a tool that requires expert oversight to validate its outputs. Its insights can be valuable but must be reviewed and refined by professionals.
Precision in formulating queries can significantly enhance the quality of results, as seen in our refined analysis of individual user interests.
The data analysis also revealed a notable trend: in 2024, the Zartis community showed a strong interest in AI topics. This insight can guide future content and engagement strategies, ensuring that the service continues to provide relevant and engaging materials for our audience.
FAQ
Q. What version of ChatGPT did you use?
A. I used the latest ChatGPT-4o.
Q. Do you trust ChatGPT’s results?
A. Only if I can verify them myself.
Q. How fast were the responses from ChatGPT?
A. Extremely fast – responses came within a couple of seconds.
Q. How big were the files?
A. Each year of Slack threads was around 5MB.
Q. Did you really need to write the anonymizer?
A. Yes and no. While I didn’t find anything useful online, I enjoyed writing some code myself.
Q. What precautions do you take when using ChatGPT for data analysis?
A. I ensure all data is anonymized and treat every response with caution, verifying results when necessary.
Q. How did you handle sensitive information in the Slack data?
A. Sensitive information was redacted and stored separately, ensuring privacy while still allowing for necessary data analysis.
Q. What types of data did you analyze?
A. I focused on identifying the top topics and most active users, as well as cross-referencing user interests.
Q. What are some limitations of using ChatGPT for data analysis?
A. ChatGPT can misinterpret data and produce irrelevant results, which requires careful oversight and additional “expert” review.
Q. Where can I find the Slack data anonymizer tool?
A. In my GitHub repository: https://github.com/abinkowski94/slack-data-anonymizer
TL;DR
In this article, I describe how I developed a .NET console app to anonymize and aggregate Slack data for analysis with ChatGPT-4o. The console app tool handles sensitive data cautiously, ensuring privacy. ChatGPT provided quick insights into popular topics and active users, but the results required verification and refinement. The project underscored the value of programming skills in solving data-related challenges and highlighted Zartis’s strong interest in AI topics. Despite ChatGPT’s capabilities, manual oversight is crucial for accurate and reliable results.
Author:
