
Artificial Intelligence moves fast. Recently, a new development has shaken both technical and business communities, DeepSeek-R1. Released in January 2025 by DeepSeek, a Chinese AI company backed by the hedge fund High-Flyer Quant and R1 is built on the DeepSeek-V3 foundation, and introduces a family of models ranging from 1.5B to 671B parameters, all under the commercial-friendly MIT-license.
This article takes a look at DeepSeek-R1: what it is, why it stands out, use cases, and how it’s reshaping how enterprises build, deploy, and cost for AI systems.
1. Overview: The New Contender in Town
Historically, the biggest large language model providers, such as OpenAI, Anthropic, Google, have guarded their models, requiring pay-per-use APIs and restrictive licenses.
Impact of DeepSeek on the AI Industry
DeepSeek’s release of its R1 model sent shockwaves through global markets. This development triggered a massive sell-off in AI-related stocks, with companies like NVIDIA experiencing substantial market loss of $600 billion in a single day.
In response to DeepSeek’s disruption of the Industry, major AI providers have been forced to reassess their pricing models and service offerings:
- Google’s Gemini: Introduced more affordable models, such as Gemini 2.0 Flash-Lite, with input costs as low as $0.075 per million tokens, aiming to provide cost-effective solutions to retain and attract customers.
- OpenAI’s o3 Early Release: Accelerated the launch of its O3 model and increased usage limits for users, as it tries to maintain its competitive edge in the rapidly evolving market.
- Chain of Thought Prompting: This technique is now offered by virtually all AI providers, after DeepSeek has proved it can be implemented economically.
- Open-Source Models: With a massive 671B-parameter model available for free, distillation is now more accessible to open-source developers.
These changes are making AI more accessible and affordable, pushing businesses and developers to rethink how they invest in and adopt AI technologies.
A Family of Models, One MIT License
DeepSeek-R1’s original model is the 671B model; however, there is a family of distilled models built on the Qwen or Llama models, ranging from 1.5B to 671B parameters. Each variant fit different use cases better:
- R1 1.5B: Perfect for small-scale AI.
- R1 7B, 8B, 14B, 32B: Balanced solutions with good language and reasoning performance.
- R1 70B: A large-scale model that can handle more enterprise workloads, including advanced RAG (Retrieval-Augmented Generation) systems.
- R1 671B: The flagship “Behemoth” for the most complex tasks, offering advanced coding, math, and logical reasoning capabilities.
All of them come under the business friendly MIT license, enabling commercial use, modification, and redistribution.
2. Why R1 Matters: Privacy, Cost, and Architecture
DeepSeek-R1’s core features are privacy, cost efficiency, and quality.
2.1 Privacy
There’s a crucial distinction between DeepSeek Cloud provider and DeepSeek the model:
DeepSeek Cloud provider:
- Offers DeepSeek API & App at competitive rates
- Not recommended for privacy-sensitive or GDPR-compliant use cases
- Hosted in China, subject to Chinese data regulations
- Chinese authorities may have access to queries and usage data
DeepSeek Model:
- Open-weight model (essentially a large array of numbers)
- Can be run locally using open source model runners
- Provides a highly secure and private deployment option
- Users retain full control over the model and its operations
This section will focus on the DeepSeek Model and its local deployment options:
Fully Open-Source Weights
Unlike closed-source models such as GPT-4 or corporate-limited “open” alternatives, R1 offers complete transparency. The code and model weights are publicly available, letting researchers and developers audit or extend them. For industries where data confidentiality is important (healthcare, finance, legal), being able to run R1 on air-gapped systems is a requirement in those cases.
Note: It’s not recommended to use the Cloud API provided by DeepSeek if you have any privacy concerns. As always, we advise not to share any private information with third parties, unless you can guarantee that it’s safe. However, for initial setup and basic development, it could be acceptable.
MIT License: A Blank Check for Innovation
R1 stands out from models that come with usage restrictions. The MIT license explicitly allows:
- Commercial Use: No royalties, no hidden fees.
- Modifications: Fine-tune, reduce, or even expand the model.
- Redistribution: Bundle it into products or services you plan to sell.
This open environment enables an ecosystem of community contributors who optimise, extend, and share new training recipes without worry of legal complications.
2.2 Cost Revolution
DeepSeek-V3’s $6 million fine-tuning cost, compared to GPT-4’s hundreds of millions, it’s a major disruption and signals a shift in AI accessibility. Now the financial barriers for smaller players are easier to overcome, enabling more competition and fostering innovation, diversification, and customization.This could lead to more cost-effective AI solutions, reduced reliance on tech giants (OpenAI, Google, Meta), and greater transparency. The key question remains: can these smaller-budget models match the quality of their expensive counterparts? It seems deepdeek proves that this is possible
In addition, R1 cuts AI operational costs by 90-98% compared to OpenAI’s o1:
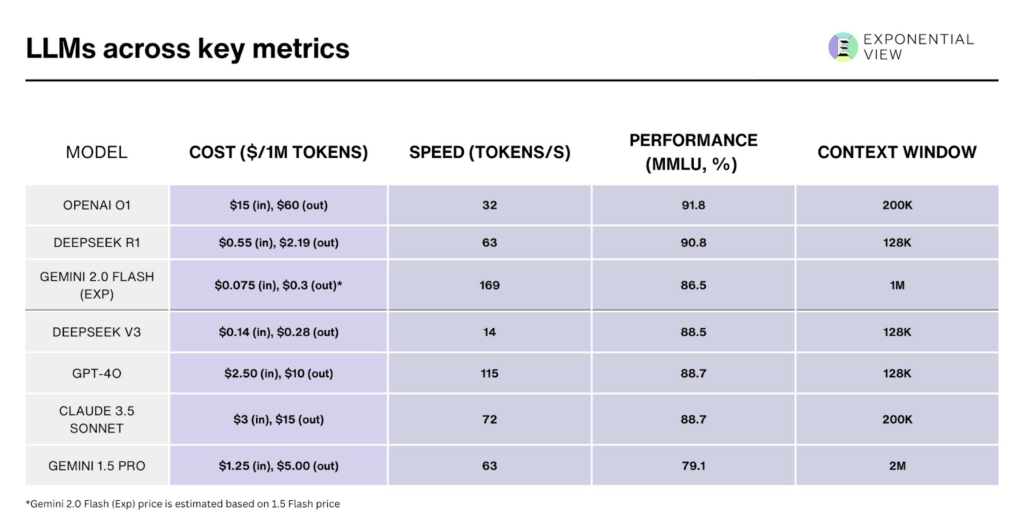
(Above numbers are estimated based on public disclosures and user-reported benchmarks.)
Why is DeepSeek-R1 so cheap compared to OpenAI’s models?
- Mixture-of-Experts (MoE) Architecture: Although the largest R1 has 671B parameters, only ~37B get activated on a given query. This drastically cuts compute overhead.
- Multi-Head Latent Attention (MLA): A specialised attention mechanism that cuts memory usage (KV cache) by up to 50% compared to standard transformers.
- Efficient Training Setup: DeepSeek claims they used 2,000 NVIDIA H800 GPUs (instead of 16,000+ for GPT-4) with their proprietary replacement of CUDA, to train the 671B model. Less training compute translates to lower inference costs as well.
- FP8 Mixed Precision: DeepSeek-R1 adopts FP8 quantization for MLA computations, improving numerical stability and efficiency. This approach reduces memory footprint by ~40% compared to BF16 and enables 2.3× faster inference throughput for long-context tasks13
The net result? R1-based applications can run at 90–98% lower cost than comparable closed-source solutions without sacrificing too much performance in tasks like code generation, text summarisation, or advanced reasoning.
2.3 Architectural Breakthroughs
DeepSeek’s earlier model, DeepSeek-V3, set the groundwork but fell short of top-tier competitors. In R1 there were few key innovations:
- Reasoning Engine
- Group Relative Policy Optimisation (GRPO): A reinforcement learning approach that merges policy and value functions. This method eliminates the need for separate “value models” during fine-tuning, streamlining the reasoning process.
- Chain-of-Thought (CoT): Allows R1 to articulate its step-by-step thought process, improving multi-step tasks like mathematics, coding, and logic puzzles.
- Hybrid Training Regimen
- Combines supervised fine-tuning (SFT) on curated “reasoning” datasets (like MATH-500, code puzzles, advanced QA) with RL-driven episodes.
- Yields a more generalised problem-solving ability while preserving robust language understanding.
- Distillation Magic
- Each smaller variant (1.5B, 8B, 32B, 70B) is distilled from the 671B “teacher” model.
- Despite size reduction, these distilled models retain 85%+ of the large model’s coding and math proficiency.
- R1-32B reportedly outperforms GPT-4o on certain coding tasks (e.g., SWE-bench) by margin points.
3. Benchmarks: Where R1 Shines
DeepSeek-R1’s strength is particularly evident in logic-heavy and coding-oriented tasks. Below is a snapshot of how it compares against GPT-4o and Claude 3.5 on a range of benchmarks:
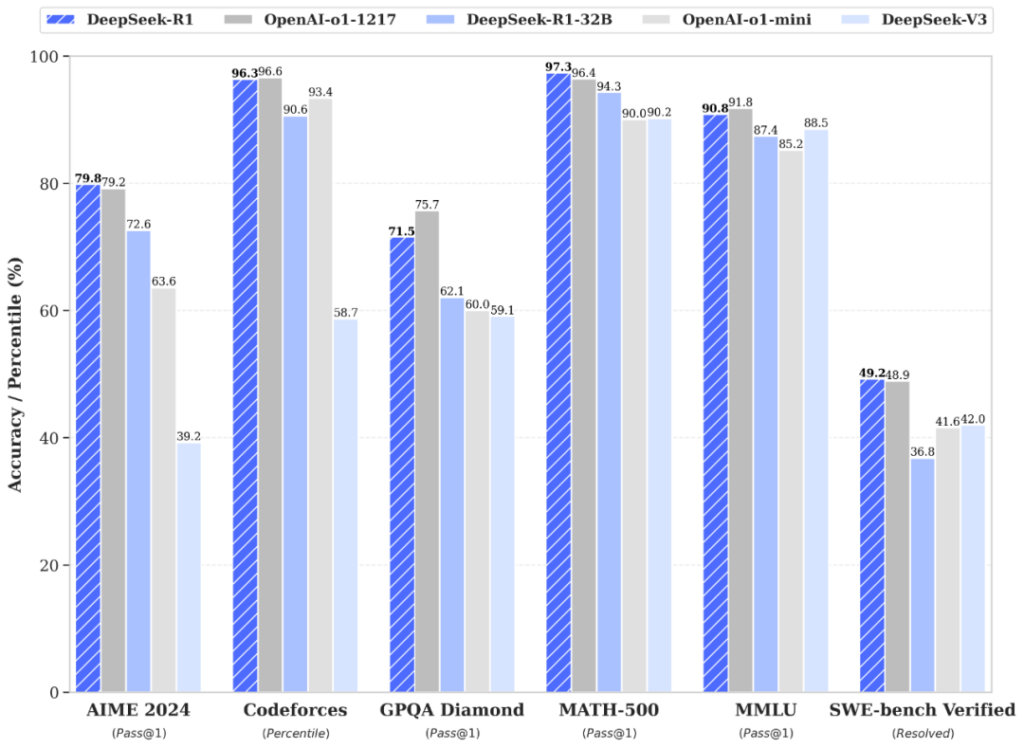
- MATH-500: A carefully curated set of math word problems.
- Codeforces Elo: Competitive programming ranking.
- MMLU: Tests broad knowledge across 57 subjects.
- AIME 2024: High-level math competition.
4. Real-World Use Cases
DeepSeek-R1 excel specifically in logical tasks, its open nature and cost efficiency open the door to a myriad of applications across industries.
4.1 Coding & DevOps
- R1-32B: Can write Kubernetes manifests and Terraform configs.
- R1-671B: Outperforms GPT-4o by 23% in solving LeetCode hard-level problems, particularly when multi-step logic or advanced data structures is a big factor.
4.2 Financial Modeling
- R1-8B: Fine-tuned on stock market time-series data, it can be used to generate market trading signals.
- R1-70B: Ingests up to a 128K token context window to identify accounting anomalies like Bloomberg GPT.
4.3 Scientific Research
- R1-Zero (an experimental sub-variant): Reportedly used in protein folding simulations, similar to AlphaFold3’s method, but 40% cheaper.
- Medical Diagnostics: Achieves 87% accuracy on the MedQA test suite. This is still below GPT-4’s ~92.8%, but at a fraction of the cost, making it extremely attractive for resource-constrained institutions.
4.4 Chatbots & Customer Interaction
- For general Q&A, the smaller models (1.5B to 8B) are capable of simple responses, but at least 32B is recommended. They run on everyday hardware and integrate easily with CRM systems, drastically reducing overhead compared to pay-per-API LLM services.
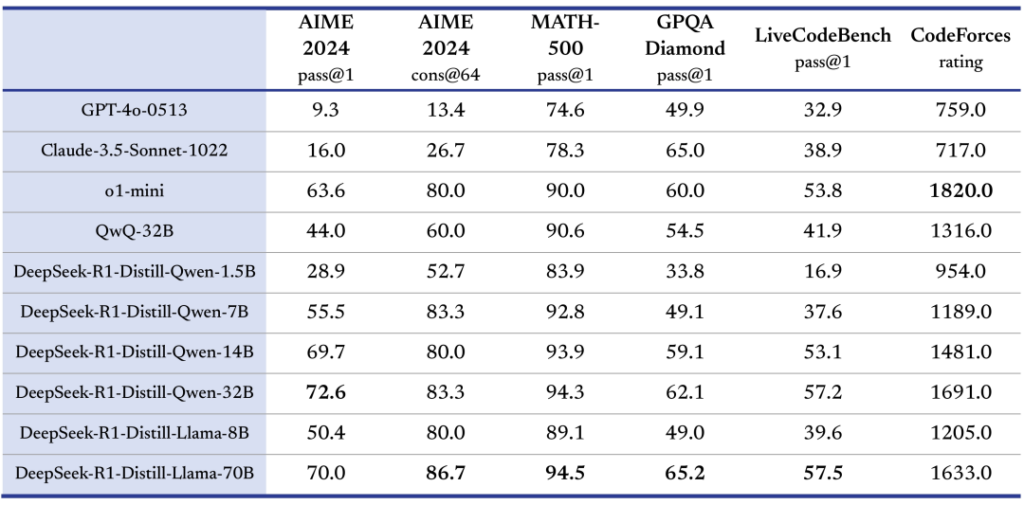
Here is some comparison of the different performance of R1 Models:
5. The Catch? ⚠️
- Language Mixing: R1 was trained heavily on English and Chinese data. Struggles with non-English/Chinese queries (like Spanish or Arabic), and it sometimes mixes languages mid-response, leading to confusion.
- Prompt Sensitivity: Oddly, zero-shot prompts often outperform few-shot prompts. The model can become over-fitted to the instructions, ignoring or contradicting them.
- Creative Writing Limitations: R1 is a logic-first model, so If you need a model for fiction, narrative structure, or creative brainstorming, GPT-4o or Claude might still be better. R1 is heavily optimized for logic, reason, and code.
- Data privacy and compliance: This is an important key concern in today’s AI is Data Privacy. We are already seeing countries like Italy have already taken regulatory action, temporarily banning certain AI tools over concerns related to GDPR compliance and how those tools handle personal data. While Deepseek’s open weights offer a privacy-first approach, offering organisations a secure solution, the API Cloud Solution DeepSeek, which is easily accessible, does not comply with GDPR guidelines.
6. The Future of Open-Source AI
For years, the AI field has gravitated toward closed-door solutions. While some small open-source LLMs gained traction, they rarely matched the performance of proprietary models.
R1 changes that narrative by delivering near vendor LLM results without the high price tag or licensing issues. Here’s what that implies:
- Decentralised AI: Users no longer have to rely solely on big tech for advanced models. Independent developers, startups, and enterprises can directly integrate R1 without monthly API fees or uncertain service changes.
- Accelerated Innovation: The permissive license fosters an ecosystem of community-driven improvements. We could see forks for specialised domains, such as R1-bio for genomics, R1-legal for contract analysis, or R1-defense for cybersecurity.
- Democratizing Access: Lowering the compute and cost barriers means more universities, research labs, and even high school science clubs can experiment more with LLM technology.
7. Getting Started: A Quick Dive
If you want to test-drive DeepSeek-R1 locally, you can use tools like Ollama:
Example: Running the 8B model locally

Or, for those who have High-Preformance Computing (HPC) needs:
- AWS Bedrock: Deploy the 70B or 671B model on ml.p5e instances.
- On-Prem Cluster: Large enterprises can download the model weights from DeepSeek’s GitHub or Hugging Face repository. With some multi-GPU servers, you can run the 70B or 671B variant in-house.
8. Conclusion: A New Era of Enterprise AI
DeepSeek-R1 has proven that open-source and high performance are not mutually exclusive. By emphasising reasoning, affordability, and transparency, DeepSeek shows the AI community that we can push boundaries without locking out smaller players or ignoring privacy concerns.
Whether you’re a developer wanting to fine-tune your own agent, a financial analyst seeking cutting-edge modeling, or a startup founder building the next GPT competitor, R1 provides a flexible toolkit that’s powerful and accessible.
In a world where AI is rapidly evolving, R1’s success story underscores the value of collaborative innovation. It suggests that, moving forward, the AI landscape will be shaped not just by a few major corporations but by a diverse global community; each making their own modifications and improvements on top of an openly available foundation.
Ready to explore what AI can do for you? We can help advise on the best solutions for your needs – whether it’s A Deepseek Model such as R1, or other AI tools. Our expertise spans fine-tuning models, building AI Agents, or implementing custom AI platforms to meet your unique requirements. Contact us and let’s discuss how we can help.
Author:

