
This article delves into the essential techniques, challenges, and tools that define the data preprocessing workflow, highlighting its significance in the success of machine learning and analytics projects.
1. Understanding Data Preprocessing: Definition and Importance
The importance of this step cannot be overstated; it directly affects the quality of insights obtained from the information. For instance, normalization plays a key role in analyzing stock performance across different currencies, allowing for a fair comparison despite varying scales. Insufficient preprocessing of data can result in errors, inconsistencies, or irrelevant information, ultimately leading to inaccurate conclusions and flawed decision-making.
2. Key Steps in the Data Preprocessing Workflow
-
Information Collection: This initial phase involves gathering information from a variety of sources, ensuring alignment with analysis objectives.Effective information collection methods significantly influence the subsequent phases, as precise and pertinent details are foundational for quality outcomes.
-
Information Integration: In this step, information from disparate sources is combined into a unified dataset. SQL Server facilitates this process by allowing users to export information into various formats, such as Excel, CSV, and JSON, which enhances the integration capabilities across different systems.This flexibility is essential for effective preprocessing of data, as it ensures that information can be seamlessly integrated from various sources.
-
Data Cleaning: This critical step focuses on identifying and rectifying inaccuracies, removing duplicates, and addressing missing values. The SQL DISTINCT clause serves as a practical example of cleaning, retrieving unique values and eliminating duplicates.For instance, when examining customer information, applying the DISTINCT clause can help ensure that each customer is represented only once in the dataset, which is vital for maintaining integrity and ensuring precise analysis.
-
Data Transformation: In this stage, the information is converted into a suitable format or structure for examination. This may involve normalization or encoding categorical variables, ensuring that the data is compatible with analytical models.
-
Data Reduction: To enhance analysis efficiency, this step simplifies the dataset by reducing dimensions or selecting relevant features. This process can significantly enhance performance and decrease computational load.
-
Data Splitting: Finally, the dataset is divided into training and testing sets.This division is crucial for assessing system performance, aiding in confirming that the system generalizes well to unobserved information.
Effective information preparation enhances machine learning model performance by ensuring that the input provided to the model is accurate, consistent, and pertinent.
 Each box represents a step in the data preprocessing workflow, and the arrows indicate the sequential flow between steps.
Each box represents a step in the data preprocessing workflow, and the arrows indicate the sequential flow between steps.
3. Essential Techniques for Effective Data Preprocessing
-
Data Cleaning: This step addresses missing values, either through imputation or removal, corrects inaccuracies, and eliminates duplicate entries. Interestingly, in a recent examination, it was found that the Wind, Temp, Month, and Day columns exhibited a 0.00% percentage of missing values, indicating a well-prepared dataset.
Selecting the suitable approach for managing absent information relies on comprehending the patterns and the consequences of each method. -
Normalization: Adjusting numerical values to a shared range is crucial, as it guarantees that no single feature excessively impacts the analysis. Normalization can significantly improve the performance of algorithms sensitive to the scale of information.
-
Encoding Categorical Variables: Techniques such as one-hot encoding and label encoding convert categorical information into a numerical format, making it suitable for machine learning algorithms. This transformation is crucial for ensuring that systems can effectively interpret and learn from categorical features.
-
Feature Selection: Identifying and selecting the most relevant features can dramatically enhance performance while reducing complexity. This process aids in concentrating on the most influential variables, thus enhancing the model’s predictive abilities.
-
Transformation: Implementing transformations, like logarithmic scaling, can stabilize variance and assist in making the information more Gaussian-like. This is especially beneficial in organizing information for regression evaluations.
Consider the potential biases and implications of the chosen method on your evaluation,
Each branch represents a preprocessing technique, with color coding indicating different categories of actions or considerations within each technique.
4. Navigating Challenges in Data Preprocessing
-
Dealing with Outliers: Outliers pose a risk of distorting statistical evaluations. It is essential to identify outliers through visualization techniques, such as box plots or scatter plots, and to determine whether to remove or transform them based on their influence on the overall dataset. Effective outlier detection techniques can significantly improve the reliability of the outcomes.
-
Inconsistency: Irregular formats across various sources can lead to erroneous interpretations. Standardizing formats not only ensures consistency but also facilitates smoother integration and analysis of datasets. This step is essential for preserving information integrity throughout the preprocessing of data phase.
-
Scalability Issues: As datasets grow, initial processing tasks can become more resource-demanding. Implementing efficient algorithms or utilizing distributed processing frameworks can alleviate these scalability concerns, enabling organizations to manage larger datasets without a corresponding increase in resource usage.
The central node represents the overarching topic, with branches indicating key challenges and sub-branches detailing specific techniques or strategies related to each challenge.
5. The Role of Data Preprocessing in Machine Learning and Analytics
-
Improved Model Accuracy: Well-structured and clean inputs empower algorithms to recognize patterns more effectively. For instance, an examination of SVM classification revealed that systems with 20% missing values achieved an accuracy of only 22.49 and an AUC of 0.701, underscoring how inadequate information quality can hinder performance. Conversely, proper preparation can markedly enhance outcomes. Notably, few studies have evaluated the combined effects of normalization and missing value handling on classification accuracy, indicating a gap in current research that could be addressed in future studies.
-
Enhanced Efficiency: Techniques such as dimensionality reduction not only streamline the information but also accelerate training times, thus improving overall model performance. Recent evaluations show that while the delete strategy for missing values resulted in the lowest generation times, the kNN technique exhibited the highest, highlighting a trade-off between efficiency and accuracy in data preparation methods. This highlights the necessity for thorough evaluation of preparation options according to particular project needs.
-
Enhanced Decision-Making: Quality information produces dependable insights, allowing organizations to make knowledgeable choices based on precise analytics. In the study titled ‘Performance Evaluation of Classification Models,’ it was demonstrated that the selection of data preparation methods profoundly influences classification accuracy, with specific combinations leading to better results based on dataset characteristics. The results of this study demonstrate that the appropriate preparation techniques can significantly enhance model performance, emphasizing the significance of this phase in the analytics pipeline.
Investing time in the preprocessing of data is not merely a preliminary step; it is a fundamental component that significantly impacts the success of machine learning and analytics initiatives.
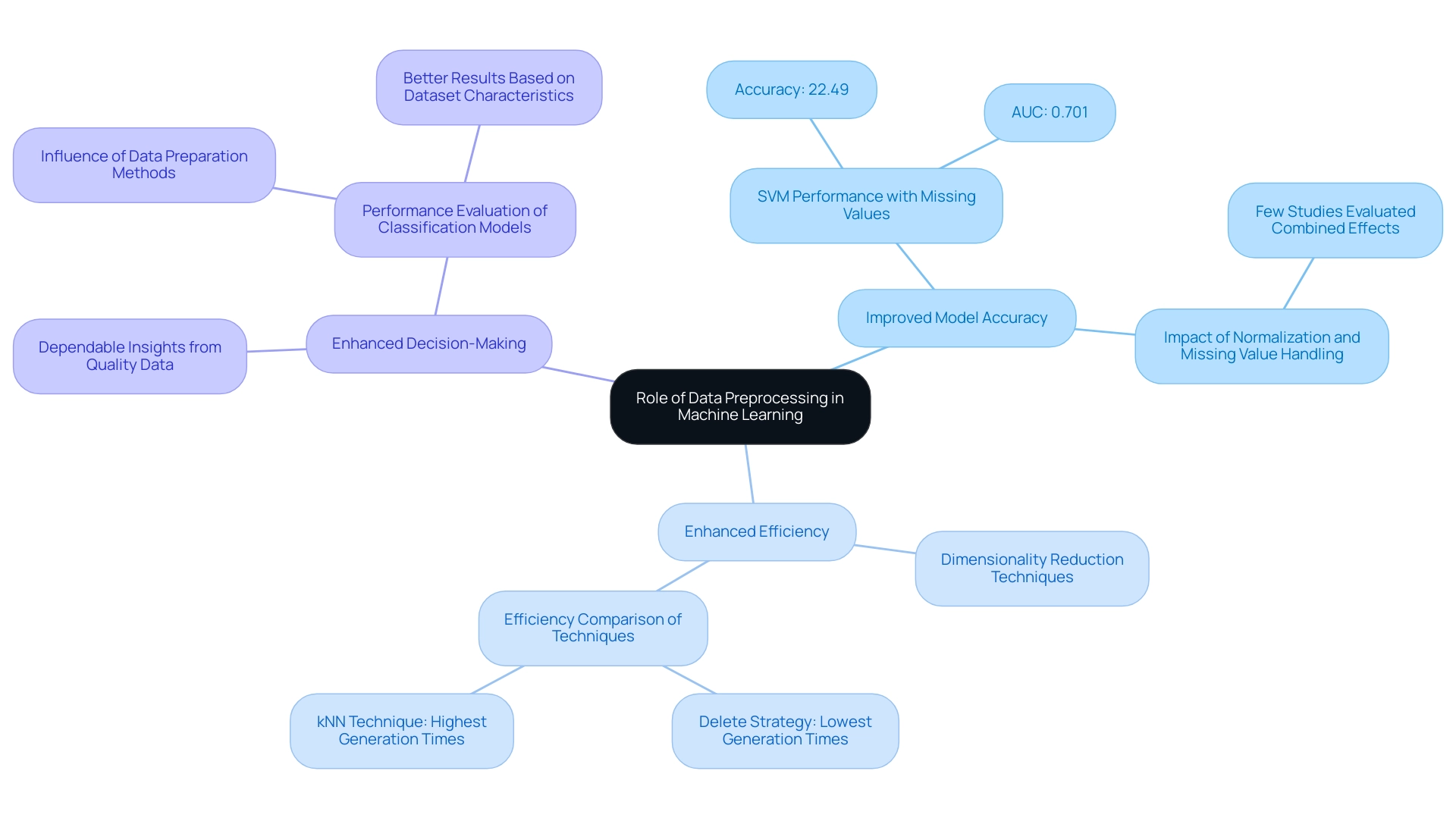
Branches represent key advantages of data preprocessing: colors indicate different benefits, and sub-branches provide supporting details and examples.
Conclusion
- Data cleaning
- Normalization
- Feature selection
Ultimately, the importance of data preprocessing cannot be overstated. It not only enhances model accuracy and efficiency but also empowers organizations to make informed decisions based on high-quality analytics. As reliance on data-driven strategies continues to grow, investing in robust preprocessing techniques will be essential for achieving success in machine learning and analytics initiatives. Embracing this foundational phase is a strategic move that can lead to significant competitive advantages in today’s data-centric landscape.
If you are looking for guidance on how to optimise your data processing and utilisation, feel free to reach out to us!