
It has only been a moment since the advantages of microservices surpassed those of monolithic systems, which has left little room for changes and innovation, thus far.
A monolithic application would be developed as a single unit. To make any iterations, an engineer would need to deploy an updated version of the server side application. Microservices, on the other hand, are developed with business-oriented APIs to encapsulate a core business capability. The principle of loose coupling helps eliminate or minimize dependencies between services and their consumers.
However, the microservices architecture has its own challenges, especially when it comes to keeping track of all updates going out simultaneously. One way to make sure you are not deploying a microservice with broken code, is to have a system in place for testing microservices – which is inherently different from testing a monolithic system.
This article summarizes a webinar on Testing Microservices, hosted by Piotr Litwiński, Principal Engineer at Zartis. You can watch the full webinar here.
Why do we test microservices?
First of all – For peace of mind. In practice, testing microservices can help us eliminate many problems by avoiding a domino effect.
The biggest issue in a distributed environment is that you have a lot of moving parts within the systems and subsystems. It’s constantly changing, and a lot of services are interacting with each other simultaneously.
Imagine that you have 10 teams, constantly working on various aspects of your systems and subsystems, deploying multiple times a day. Without proper testing, you might experience some side effects because you weren’t aware of the changes made by other team members. This gets very complex and in case of a mistake, the rollbacks are usually quite substantial. Because of the dependency tree, taking out one of those microservices from the system might be difficult, as that usually implies you need to also revert other deployments which are dependent on this microservice.
The Testing Pyramid
Let’s talk about what types of tests there are, how they cover different areas of your software and how they work together. The testing pyramid, which is a common concept today, is a good place to start.

At the bottom of the pyramid, we have tests that are cheap, fast and easy to develop – for instance, unit tests. The further up we go, the more complex the tests get. In addition to being more expensive to develop and maintain, they also run slower. Functional tests are usually easier to group with more classes, but they also have more lines of code. And then you have integration tests which are usually interacting with something else. With end-to-end (E2E) tests you can test your whole system or subsystem, which means a lot of configuration.
There are various tests that you can use, but the bottom line is that you need to plan how you want to test various features. Sometimes it might be enough to test it on the unit level, but sometimes it’s just not possible because the feature is too complex or not reliable enough to test on lower levels.
The idea is that you know the testing parameters and can plan the test layers that go one on top of another. This way you can rely on things that are lower in the pyramid to be covered and test the things that you know couldn’t be covered on lower layers.
Here is how setting up different testing layers looks in practice:
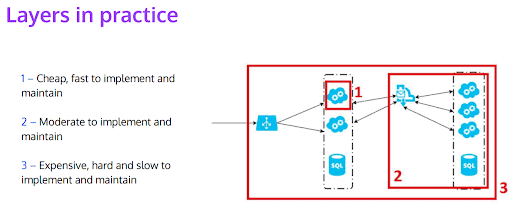
To study the diagram above, let’s assume that we have two services and there’s a load balancer sitting in front of them. When a request comes to a load balancer, it gets distributed to one of the services. Then that service translates those requests into messages and we see a message bus there, which is communicating to another service. There are multiple instances of that service, which are listening to changes reported by that message bus.
The idea is that you can test within your service itself, using the cheaper and faster methods to implement tests, represented by no.1 on the diagram above. The second layer of tests should add on to this, for instance, using a local counterpart, plugging in a local database, adding a Docker container etc. This way you can test integrations. Third layer of tests is the slowest and hardest to develop and maintain. When you are testing everything together, you need a proper environment to deploy it, run it, see the results, and wait for the results. What’s more, if something fails, it’s not that easy to actually see what went wrong, and it may require further investigation.
When is it critical to implement all levels of testing and when is it too costly to consider?
This really depends on the feature you’re implementing. If it’s not necessarily “business critical”, maybe you do not need to implement all layers. At the same time, if it’s the core part of your business, it’s probably good to have everything covered with all layers of testing. However, given that you are building layers upon layers, tests are not really that expensive, because you would have a lot of building blocks in place already. The more familiar you are with those techniques, the easier it is to follow.
Let’s take a deeper look into all these types of tests and how you can set them up!
Build-time Tests: Layer 1 and Layer 2 Tests
First and foremost, we have the classic Unit tests, and then there are other things you can deploy, such as testing your contracts. Contract tests are extremely important, if you can’t go back scoping your services and your modules. You can base all that on the contracts and test those things in isolation, so that you’re making sure that your contracts are not changed accidentally.
Imagine you have API responses, let’s say Asp.NET, and you’re replying in JSON. Your contract tests will verify if you still have the same capitalization and if order properties are still the same. It’s very easy to change the way you’re presenting the data and if someone uses JSON and forgets to change back to XML.
Then you can have Service/Components/Functional tests. In these types of tests, you need to use a lot of in-memory counterparts, emulators, stripped down versions of real services and everything is running on your machine. So it is not necessarily just running on the same process but everything is running locally.
Last but not least, we have Single-Service Integration tests. Let’s say, you’re developing on a dynamic DB instance on AWS and you’re trying to run a test against that. Usually, you can use some other counterparts, but sometimes there are edge cases that cannot be covered otherwise. Here it’s worth mentioning that this is mostly white box testing, which means that you know what you’re looking for. So, you need to know how this stuff works internally, if you want to write these kinds of tests.
Environmental Tests: Layer 3 Tests
Here, as the name suggests, you need some sort of environment and it doesn’t need to be a full environment, but you need more than one service or system component to test. To that end, you can use simulators to test services running at the same time.
There are a few groups of tests that can be grouped as environmental tests. One of them is Deployed Tests. Deployed tests run instantly after a successful deployment and the purpose of this test is to verify if everything was configured properly. This means that you don’t focus too much on the logic, but test things such as having access to the database when you send a message; if that message is being processed properly to that column; if you have access to all the resources that your services need etc.
Then we have End-to-end (E2E) Tests. They’re usually more focused on use cases. Here, you would use an API and then expect some sort of notification being sent back by your system or subsystem.
Next group of tests is Startup Checks. They are similar to Deployed Tests, but they’re less flexible which means that this is actually part of the deployment process of your service. The idea is that you program tests for certain verifications and checks at the startup and you make sure that when your service is deployed, that you can, for instance, access the database, if the database schema is in the correct place, if the API’s that you are using are in the correct versions etc.. These Startup Checks will help you verify if everything that your service relies on is actually working as expected, using the correct versions, and so on.
Last but not least, we have Exploratory Tests. They’re semi automatic and mostly developed by QA team members. To some extent, you can actually run a series of automated tests to figure out if there are any ways to break up the services that are being tested. It is worth mentioning that these tests are usually a mix of white box and black box tests, because for E2E or Exploratory Tests, you really need to know how stuff works internally.
To sum up, build-time tests are focused heavily on the logic of your service, so you basically make sure that if you flip the switch, it reacts in the correct way. Whereas environmental tests are basically testing things from a configuration standpoint such as wrong passwords, expired certificates, etc. The purpose of environmental tests is to detect these kinds of issues, and act like a smoke test.
System Tests: Layer 3 Tests
There are two more test groups that fit into the third layer tests, which are Performance Tests and Resilience / Availability Tests. Using these system tests, you can test your whole system or part of a subsystem depending on how you want to slice your tests.
Performance testing is related to the performance of your services. Setting these tests is tricky because you usually don’t need to have a full scale test environment, but you need to scale it up or down, or tailor it to be close enough. Instead of running 10 services, you can run 2 and if those two services can hold that much load, then it means the tank can hold 5x more, right? These tests should simulate the real traffic and show how the performance holds in various scenarios.
Resilience/Availability testing is more about how your system behaves, in case something goes wrong. Imagine that you have 20 services, and one of them is down. Does that conflict break the whole system down or is it just causing a system to operate with a warning like ‘Currently, you don’t have access to X part of the system, but the rest is still up and running’?
Here, it’s worth mentioning the importance of tracing for both Performance and Resilience tests. You can have hundreds or even thousands of processes, machines, containers and when you need to figure out where the problem is, having logs and metrics in place can save you a lot of time. You can either manually check the logs to see if there are any overflow of errors, if there are metrics that are indicating some issues, or you can also set automated alerts to get notified of issues in real-time.
Pros and Cons of Testing Microservices:
Challenges of Testing Microservices

Standardization On a Company Level
The challenges of implementing the techniques we talked about above are usually related to standardization because some of these techniques require processes at company level. Automating processes at this level can be very difficult, because you need to get your tech team on the same page and make sure everyone agrees on a specific way of setting up the system to allow these tests.
Dependencies Get More Complex & Costly
The need to include team members working on different parts of the system means things are about to get even more complex. Creating dependencies means spending more time and therefore more money to continuously collaborate. There may also be additional costs for tools, if you don’t want to invest in building them in house. Your engineers may also need training to ease the learning curve.
If you are introducing these techniques to your team, people need to get used to them and to working in this way.
The Advantages of Testing Microservices

You may need to spend some time and resources on getting your team onboard and aligning your development and testing approach. However, in the log run, testing at lower levels has many advantages.
Huge Savings in Time and Regression
To give an example, currently we are working on regression for a client’s project and our goal is to cut down the testing time on each environment down to a couple of minutes, tops. The build time tests last four minutes, and once we deploy to an environment, the tests are running within three minutes. Altogether, the test time takes no more than 10 minutes. This is a huge win when you consider how much time it takes for an automated environment to test the whole subsystem.
Catching Bugs Earlier
The earlier you catch a bug, the faster and cheaper it is to fix. Considering the damage it could do to your business while a service is down, the cost of not catching a bug quickly can have real financial consequences.
Confidence In Refactoring Or Expanding A System
While refactoring or expanding a system, you can have the confidence that if anything goes wrong, you will be notified in real-time. Sometimes even before it goes to the production, so you don’t get a request from a customer asking why something is broken. Resolving issues before it reaches the customer will hugely increase your customer’s and team’s product confidence.
Standardisation On a Company Level
While we listed this as a disadvantage in the beginning, if done correctly, the advantages outweigh the disadvantages. Transitioning may be a challenge but once you do, everything becomes much easier from a management perspective. You can shuffle teams, and motivate people to change teams if they find different domains more interesting. Since all teams work under the same principles, with the same tools, and they have the same approach to contracts etc., your engineers will become valuable assets for different teams within the organisation.
Do you need help with your testing strategy? Zartis can help with consulting services, as well as a team of software engineers. Reach out to learn more.